
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 코딩공부
- 동성로카페
- 동성로맛집
- 수성구카페
- 지산동카페
- 범물동
- 안드로이드스튜디오
- 안드로이드개발
- 애드센스
- 대구인스타핫플
- 안드로이드앱개발
- Android
- 수성구맛집
- 코딩
- 동성로핫플
- 인스타핫플
- 어플개발
- 대구맛집
- 안드로이드
- 앱개발
- 범물동카페
- 애드몹
- 파이썬
- 감성카페
- 대구핫플
- 안드로이드앱
- androidstudio
- 의무경찰
- 대구카페
- 개발자
- Today
- Total
Glacier's Daily Log
Python) 파이썬 BeautifulSoup4를 이용해 웹 크롤링 예제 만들어 보기 본문
저번 포스팅에서는 이미지 크롤링 프로그램을 만들어 보았다.
Python) 파이썬을 이용한 이미지 크롤링 프로그램 만들기
어쩌다보니 티스토리 블로그를 이용한 첫 번째 포스팅이 파이썬 코딩 관련 글이다. 티스토리 블로그를 시작하게 된 이유는 따로 다른 포스팅으로 다루어 볼 것이다. 우연히 파이썬의 매력에 빠�
h-glacier.tistory.com
이와 같이, 파이썬을 이용해 웹사이트의 정보를 크롤링 해오려면
Beautiful Soup 4 라는 라이브러리를 사용해야 한다.
bs4 라는 명칭으로 사용되는 이 라이브러리는,
웹사이트의 html이나 css같은 정보를
모두 끌어모아 주는 역할을 해준다.
만약, bs4를 설치하지 않았거나 라이브러리를 설치해보지 않은 입문자라면
지금부터 따라 해보자.
우선

윈도우 시작키 우클릭 -> 실행 혹은 키보드 윈도우키 + R
을 해서 실행을 켠다.

그리고, cmd 라고 친 후 확인을 누른다.
"명령 프롬포트" 를 실행하는 과정이다.
그리고 명령 프롬포트가 실행되면
pip install bs4
라고 입력해준다.
pip는 파이썬을 불러오는 명령어이고, install 은 라이브러리를 설치하라는 명령어
bs4는 BeautifulSoup4의 명칭이다.

그러면 이렇게 명령어가 쭈우우욱 뜨고 설치가 완료될 것이다.
물론 나는 이미 설치되어 있기 때문에 화면이 좀 다르게 나온다.
라이브러리 설치가 이렇게 간단하게 이루어지니
파이썬의 장점이 부각되는 것 같다.
그럼 시작해 보겠다.
우선 프로그램의 시작을 알리는 인트로 멘트 부터 만들어 보겠다.
Python) 파이썬 datetime 모듈을 이용해 오늘 날짜 나타내기
코딩으로 무언가를 만드려고 하다 보면 오늘의 날짜를 나타내야 할 때가 분명히 온다. 엑셀을 공부할 때, 오늘 날짜를 표현 할 일이 많아서 NOW(), TODAY() 함수를 매우 잘 활용 했었는데 생각보다 JA
h-glacier.tistory.com
위 포스팅에서 작성했듯이
datetime 모듈을 이용해 오늘 날짜를 표출해 줄 것이다.
# 웹크롤링 프로젝트
# https://h-glacier.tistory.com/
import datetime
from bs4 import BeautifulSoup
import urllib.request
now = datetime.datetime.now()
nowDate = now.strftime('%Y년 %m월 %d일 %H시 %M분 입니다.')
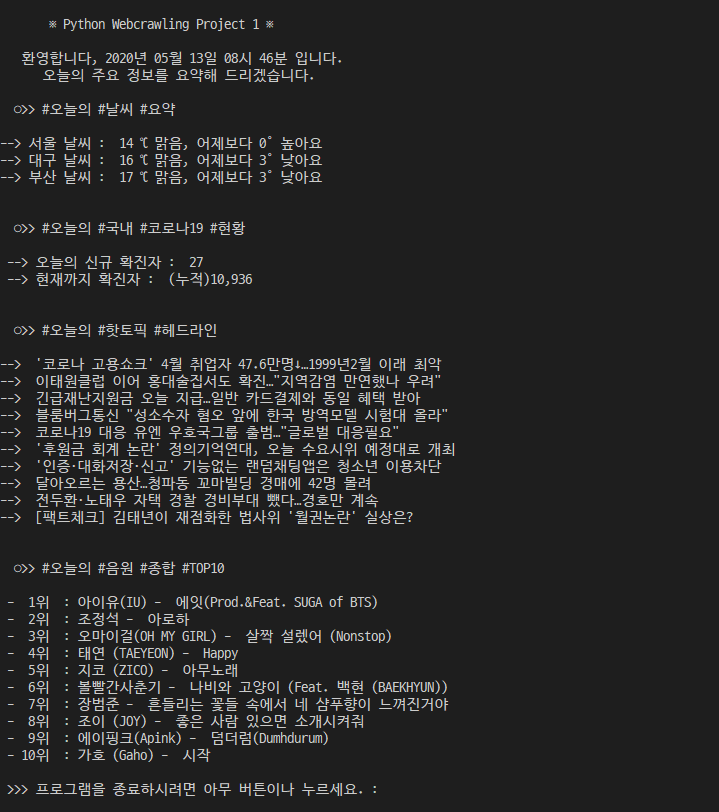
print("\n ※ Python Webcrawling Project 1 ※ \n ")
print(' 환영합니다, ' + nowDate)
print(' 오늘의 주요 정보를 요약해 드리겠습니다.\n')datetime 모듈에 관한 소스는 윗 포스팅에서 다뤘으니 생략하도록 하겠다.
그리고 이제 urllib.request
라는 라이브러리를 import 해준다.
urllib 라이브러리는 파이썬에 기본내장 되어 있기 때문에
따로 설치할 필요가 없다.
# 오늘의 날씨
print(' ○>> #오늘의 #날씨 #요약 \n')
webpage = urllib.request.urlopen('https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%84%9C%EC%9A%B8%EB%82%A0%EC%94%A8')
soup = BeautifulSoup(webpage, 'html.parser')
temps = soup.find('span',"todaytemp")
cast = soup.find('p',"cast_txt")
print('--> 서울 날씨 : ' , temps.get_text() , '℃' , cast.get_text())
webpage = urllib.request.urlopen('https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EB%8C%80%EA%B5%AC+%EB%82%A0%EC%94%A8')
soup = BeautifulSoup(webpage, 'html.parser')
temps = soup.find('span',"todaytemp")
cast = soup.find('p',"cast_txt")
print('--> 대구 날씨 : ' , temps.get_text() , '℃' , cast.get_text())
webpage = urllib.request.urlopen('https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EB%B6%80%EC%82%B0+%EB%82%A0%EC%94%A8&oquery=%EB%8C%80%EA%B5%AC+%EB%82%A0%EC%94%A8&tqi=UrZy%2Bsp0YidssAyki54ssssssKC-251380')
soup = BeautifulSoup(webpage, 'html.parser')
temps = soup.find('span',"todaytemp")
cast = soup.find('p',"cast_txt")
print('--> 부산 날씨 : ' , temps.get_text() , '℃' , cast.get_text())
print('\n')우선, 오늘의 날씨를 크롤링 해오는 소스코드 이다.
이는 네이버에 '서울 날씨', '대구 날씨', '부산 날씨' 를 검색하면 나오는 정보를
크롤링 해오는 것이다.
우선 내가 크롤링 하고 싶은 부분의 html 값을 찾아내야 한다.

나는 이 부분을 크롤링 해와서, (14'c 맑음, 어제보다 2' 낮아요) 이렇게 구현 하고 싶다.
자, 그럼 이제 소스를 추출 해 보자.
이 사이트에서 F12를 누른다.
그럼 "개발자 도구" 가 열릴 것이다.

빨간색 동그라미 친 버튼을 누른다.
그러면 내가 클릭한 부분의 소스코드를 뽑아준다.

보면 class="todaytemp" 라는 것이 보인다.
이 클래스 값을 이용해 크롤링 하는 것이다.

이 부분은 cast_txt 이다.
그러면 이제 파이썬으로 넘어가서 코딩해보자!
위에 코드를 적어놨는데 쪼개서 다시 보자.
print(' ○>> #오늘의 #날씨 #요약 \n')
webpage = urllib.request.urlopen('https://search.naver.com/search.naver?sm=top_hty&fbm=0&ie=utf8&query=%EC%84%9C%EC%9A%B8%EB%82%A0%EC%94%A8')
soup = BeautifulSoup(webpage, 'html.parser')
temps = soup.find('span',"todaytemp")
cast = soup.find('p',"cast_txt")
print('--> 서울 날씨 : ' , temps.get_text() , '℃' , cast.get_text())webpage 라는 변수에, urllib.request.urlopen("크롤링 하고자 하는 링크") 를 통해서 웹페이지를 정보를 저장해주자.
그리고 우리가 처음에 설치했던 bs4를 사용할 시간이다.
soup라는 변수에 BeautifulSoup(webpage, 'html.parser') 를 이용해서,
webpage 변수에 담아둔 html 정보를 쫘아악 크롤링 해온다.
그러면 이제 soup 변수에는 웹사이트의 html 코드가 온전히 담겨있다.
temps = soup.find('span', "todaytemp")
이부분이 제일 중요하고 핵심이다.
이제 temps 라는 변수에, soup에 담긴 html 코드 중
<span> 태그의 'todaytemp' 클래스를 찾아서 담아주는 것이다.
밑의 cast 변수에는
<p> 태그의 'cast_txt' 클래스를 찾아 담아준다.
그리고 print를 이용해서
찾아낸 모든 값을 구현한다.

어라? 결과를 보면 뭔가가 이상하다.
html 소스가 같이 불러와진다.
이는 당연한 결과이다.
bs4에서 html소스를 모두 크롤링해서 그중 span, p태그의 특정 클래스만 뽑아온 것이기 때문에
결과값에는 모든 소스코드가 같이 저장된다.
그럼 어떻게 해야하냐고?
뽑아온 temps와 cast 변수에 get_text() 를 붙이면 된다.
이는 소스를 모두 제거하고 문자데이터만 불러오는 함수이다.

그러면 우리가 원하던 대로 깔끔하게 크롤링 된다.
그러면 첫번 째 메뉴였던
오늘의 날씨 요약은 완료되었다.
그럼 이제 나머지 부분은 모두 스스로 해결 할 수 있을 것이다.

이 부분을 한번 스스로 해결 해보자.
나는 http://ncov.mohw.go.kr/ 질병관리본부 공식 홈페이지를 통해 크롤링했다.
-
-
-
# 오늘의 코로나 현황
# https://h-glacier.tistory.com/
print(' ○>> #오늘의 #국내 #코로나19 #현황 \n')
webpage = urllib.request.urlopen('http://ncov.mohw.go.kr/')
soup = BeautifulSoup(webpage, 'html.parser')
dayconfirm = soup.find('span',"data1")
allinfo = soup.find('span', 'num')
print(' --> 오늘의 신규 확진자 : ' , dayconfirm.get_text() , '\n --> 현재까지 확진자 : ', allinfo.get_text(),'\n\n')
날씨 크롤링 한 소스코드와 별 다를바 없다.

빨간색 강조한 부분을 크롤링 해 온 것이다.
이렇게 매우 간단하고 간결한 코드로
웹페이지의 내가 원하는 부분을 모두 크롤링 해 올 수 있다.
HTML과 CSS를 조금이라도 공부해본 적이 있는 사람이라면
파이썬 웹크롤링 예제는 추가 공부 없이 쉽게 건드릴 수 있을 것이다.
다음, 오늘의 핫 토픽은
네이버의 연합뉴스 속보 칸에서 따왔다.

이 부분도 스스로 해결 해보려고 노력하고
안되면 내 소스코드를 참고하자.
힌트는 위의 예제에서 쓴 find 와 다르게
find_all 이라는 함수를 사용한다.
find는 젤 먼저 나오는 하나만 찾아주는거라면
find_all은 전체 페이지에 있는 모든 것을 크롤링 해준다.
-
-
-
# 오늘의 핫토픽
print(' ○>> #오늘의 #핫토픽 #헤드라인 \n')
webpage = urllib.request.urlopen('https://www.naver.com/')
soup = BeautifulSoup(webpage, 'html.parser')
for temps in soup.find_all('a',"issue"):
print('--> ' , temps.get_text())
print('\n')find_all을 사용한것과, 이를 통해 찾은 값을 모두 뿌려주기 위해 반복문 for를 사용한 것이
가장 큰 차이다.
그럼 마지막, 오늘의 음원 TOP10

이부분은 어떻게 처리했을까?
멜론 TOP10을 하려고했지만,
멜론 사이트에서는 크롤링 봇의 접근을 차단하여 작동하지 않는다.
그래서 네이버 뮤직 TOP10을 끌어왔다.
음원차트 : 네이버 통합검색
'음원차트'의 네이버 통합검색 결과입니다.
search.naver.com
이 페이지를 이용해 크롤링 해보자.
이것도 위의 예제와 마찬가지로 반복문과 find_all 을 사용한다.
-
-
-
# 오늘의 음원 TOP10
# https://h-glacier.tistory.com/
print(' ○>> #오늘의 #음원 #종합 #TOP10 \n')
webpage = urllib.request.urlopen('https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%EC%9D%8C%EC%9B%90%EC%B0%A8%ED%8A%B8&oquery=%EB%A9%9C%EB%A1%A0%EC%B0%A8%ED%8A%B8&tqi=UrZ0HsprvN8ssK5ZP%2BsssssstVh-314088')
toptenlist = []
artistlist = []
Rank = 10
soup = BeautifulSoup(webpage, 'html.parser')
for topten in soup.find_all('div',"title"):
toptenlist.append(topten.get_text())
for artist in soup.find_all('a',"singer"):
artistlist.append(artist.get_text())
for i in range(Rank):
print(' - %2d위 : %s - %s'%(i+1, artistlist[i], toptenlist[i]))이렇게 된다.
위의 예제와 다른점은,
find_all 해서 나온값을 리스트에 담아서 하나씩 뽑아주는 것이다.
노래의 제목과 가수명을 따로 크롤링 해와야 하기 때문에
이를 한번에 print 해주려면
리스트에 담아서
반복문으로 동시에 뽑아주어야 하기 때문이다.
총 10개를 뽑을 것이기 떄문에 Rank변수에 10을 담고
반복문이 rank까지 실행되도록 해준다.
i+1, artistlist[i], toptenlist[i]
그러면 이부분이
1, artistlist[0], toptenlist[0]
2, artistlist[1], toptenlist[1]
,
,
,
이런식으로 진행되어
print 할 값에는
1위 : 아이유 - 에잇
이런식으로 나올 수 있게 되는 것이다.

그럼 우리가 처음에 만들려고 했던 그 프로그램이
똑같이 완성 되었다.
이렇게 bs4의 기본 사용법과
반복문과 함께 사용하는 법을 깨닫게 되면
거의 모든 사이트들의 정보를 크롤링 할 수 있는 능력을 가지게 된다.
더 궁금한 점이 있으면 댓글로 물어보면 될 것 같고
도움이 되었으면 공감이나 댓글 달아 주었으면 좋겠다 :)
'Coding > Python' 카테고리의 다른 글
| Python) 파이썬 웹크롤링 예제 오류 수정본 - AttributeError: 'NoneType' object has no attribute (2) | 2020.07.05 |
|---|---|
| Python) 파이썬 datetime 모듈을 이용해 오늘 날짜 나타내기 (0) | 2020.05.12 |
| Python) 파이썬으로 로또 1등번호 추첨기 만들기 (0) | 2020.05.09 |
| Python) 갑자기 내가 파이썬을 하게 된 이유 (0) | 2020.05.08 |
| Python) 파이썬을 이용한 이미지 크롤링 프로그램 만들기 (10) | 2020.05.08 |



